并发 序
经常在面试或者各种技术交流群中听到各种并发/多线程的讨论。发现自己对这块还是一知半解的状态,缺少一个整体的了解。因此本系列也算自己对并发/多线程的一些思考和总结。随笔记录,如有不正确的地方欢迎沟通指正。
场景
我们看如下的场景:
 在我们多cpu在执行不同的程序代码(数据隔离)的时候。他们是不会互相进行影响的。因为他们之间的数据及代码是独立的不涉及到共享变量的情况。
在我们多cpu在执行不同的程序代码(数据隔离)的时候。他们是不会互相进行影响的。因为他们之间的数据及代码是独立的不涉及到共享变量的情况。
那其实问题就很明确了当多cpu涉及到执行同一段代码/修改共享数据时,如下图所示:
 例如多cpu同时执行如下代码
例如多cpu同时执行如下代码
int a=a+1;
它并不是一个原子性的操作,它其中涉及到3个步骤。
- 读取b的值。
- 将b的值进行加1操作。
- 将处理完毕的数据写入到a的地址。
我们用伪代码来分别标识这3步为 load b,add, store a,那么在两个cpu同时执行的情况下大致会出现以下组合(我们以a=0为例 只列举几种情况)。
1:load a1:add1:store a2:load a2:add2:store a1:load a2:load a1:add1:store a2:add2:store a
我们能够发现出现了两种情况,情况1是我们的预期值 2,情况2得到的实际值却为 1。这明显与我们的预期值不符。我们能够很轻松的发现问题的原因,程序并没有按照我们的预期在 cpu1 执行完代码之后 cpu2 再去执行代码。那问题就比较简单了
我们该如何保证两个cpu执行代码的顺序呢?在我们进行讨论之前我们先看一下cpu获取数据进行计算的一个大致演示图1吧:
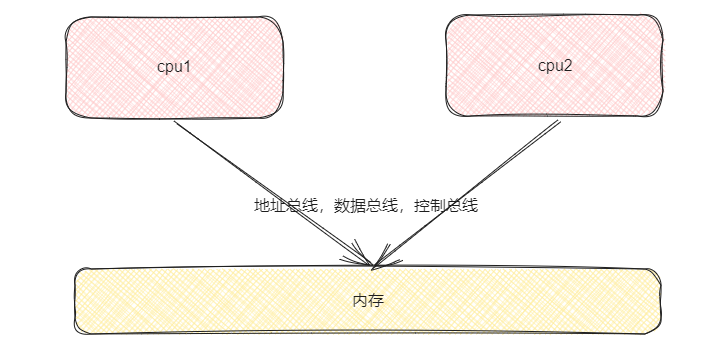 我们想要保证两个 cpu 执行代码的先后顺序,其实就是要保证
我们想要保证两个 cpu 执行代码的先后顺序,其实就是要保证 a =a+1 这行代码的原子性,即 load a add store a 三个指令同时执行完毕之后才能执行其他的指令。如上图所示 cpu 通过总线来跟内存中的数据进行交互,
那我们能不能通过在总线上添加标识的形式来告诉其他 cpu 说此路繁忙,请稍后呢。明显是可以的。在我们的 cpu1 进行指令处理的时候我们在总线上设置标识告诉 cpu2 先等一会,在 cpu1 处理完毕之后在执行操作。欸 好像确实能够解决问题,但是我们
仔细想想就能够发现。这种行为就好像是高速公路上某一车道发生了抛锚,结果我们把整条高速公路都给封闭了,等抛锚车辆处理完毕之后我们再放开高速的管制。是能够解决代码执行先后的问题,但是好像对整个与此计算无关的指令都进行了限制,代价是有
一些高的… 既然锁总线代价有些高,那我们就很自然而然的能想到一个解决方案。我们能不能只对我们用到的那个数据进行上锁?应该是可以的吧,我们要相信计算机行业前辈们的智慧👍。如下图所示,我们想要对具体数据进行上锁的话肯定就要在cpu内部
的缓存行1上进行处理了。
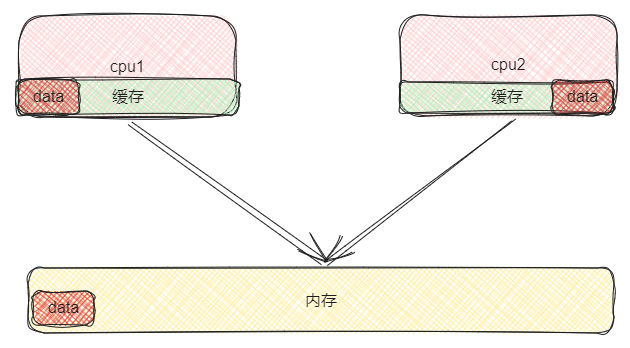 我们只需要对加载进入和cpu 缓存的数据进行加锁,既保证了数据的读取又不会太影响 cpu 的执行效率。
我们只需要对加载进入和cpu 缓存的数据进行加锁,既保证了数据的读取又不会太影响 cpu 的执行效率。
综上所述我们大致提出了两个猜想来保证 cpu 执行指令时的原子性。
- 总线锁 对整体总线进行锁定 会大幅降低 cpu 的性能
- 缓存锁 在 cpu 内部的缓存行中对具体的数据进行加锁 两种处理逻辑就类似于我们业务开发中的 Redis 分布式锁。总线锁类似于所有的业务公用同一个 key 来进行锁定。而缓存锁则是根据业务来使用不同的业务 key 来进行更细粒度的锁定。
经过上面的思考,我们能够想到这两种锁的处理逻辑必然是 cpu 开发人员提供给上层开发者的原子性操作 api。 即 cpu 提供了指令级别的原子操作,上层开发者只要基于这些原子操作就能够实现大批量指令段之间的原子性操作。
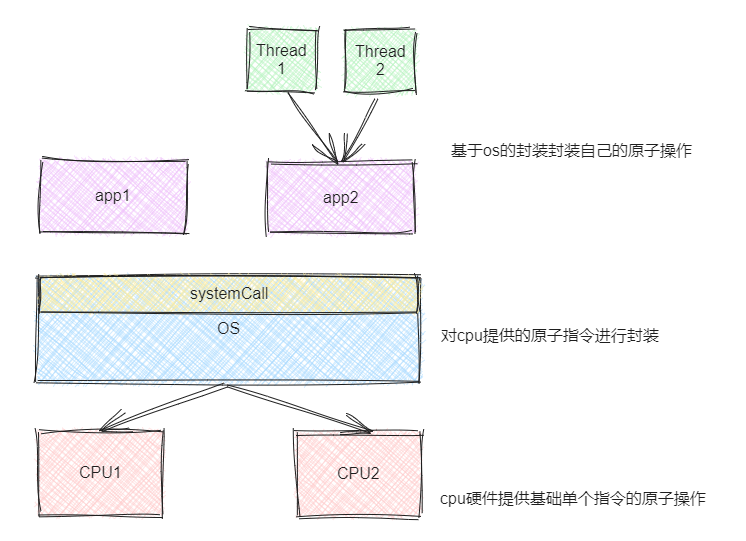
思考一下那我们该如何利用 cpu 提供的原子操作保证应用层的大批量代码段之间的原子操作呢?这就好比 cpu 提供了一块标识,来标识某个地方现在被使用。我们可以使用这个标识来当门锁在进入代码段之前进行锁定。其中一个线程在获取锁成功之后,别的 线程看到这个状态只能等待(排队),有点类似节假日期间服务区的厕所🤦♀️。当然排队这个操作必然也是需要进行加锁处理的。
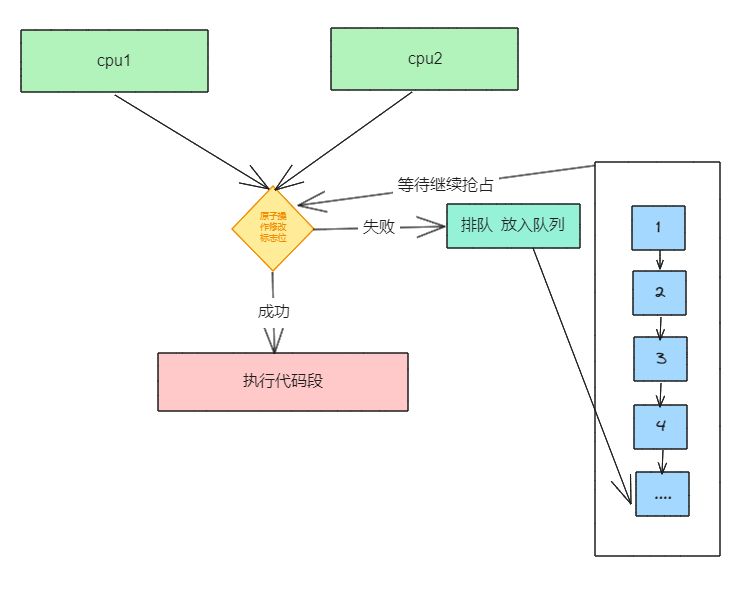 伪代猜想为
伪代猜想为
if(原子抢占标志位){
// 执行代码段逻辑
}else{
for(;;){
//自旋等待进入队列
}
}
总结一下我们今天的一些猜想:
- cpu 层面必然提供了一些基础的原子性操作指令来给上层应用开发者。
- 总线锁/缓存锁
- 通过对 cpu 提供的原子操作对上层应用的原子操作封装逻辑。